Ramp Test Makes FTP Testing More Efficient and Less Stressful
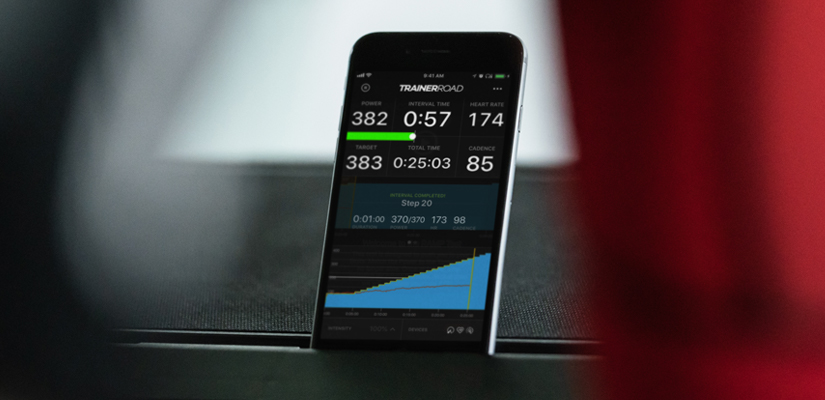
The Ramp Test assesses FTP and gradually increases power in one-minute steps until the rider cannot maintain the target power. It is the most efficient and accurate way to assess your fitness on TrainerRoad. Compared to traditional FTP tests, it hurts less, removes pacing from the equation, and takes less time to complete. After taking a Ramp Test, your TrainerRoad workouts will be automatically scaled to your fitness level.
What is a Ramp Test?
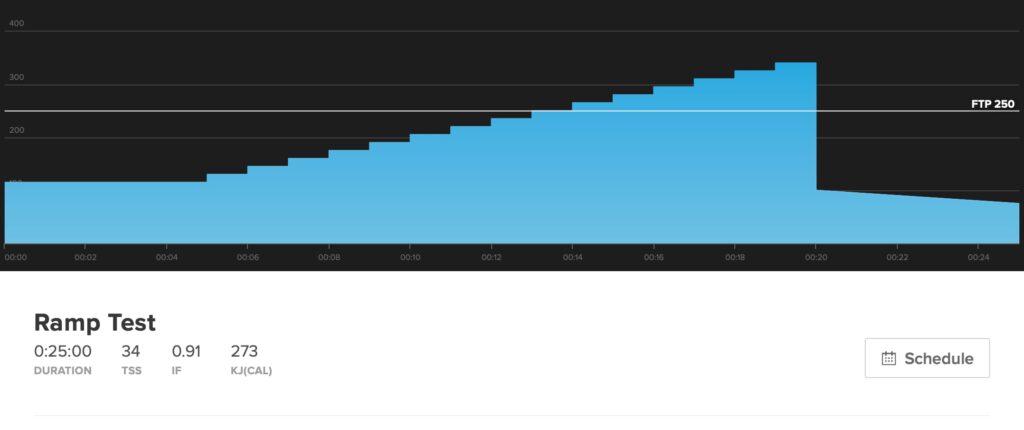
The TrainerRoad Ramp Test is an assessment workout that uses gradual increases in power to estimate FTP. Starting with a 5-minute warmup and then every minute thereafter it gets slightly harder until the rider cannot maintain target power any longer. There is no success or failure in the Ramp Test, instead it is designed to find the limits of your ability and capture the most accurate possible snapshot of your fitness.
If you choose to accept the results, the FTP estimate established by the ramp test is automatically applied to your future workouts, customizing your training based on your fitness level. Riders should ideally take a ramp test every 4 to 6 weeks to ensure their workouts keep pace with their current abilities.
Goals of the Ramp Test
The Ramp Test is an assessment of your fitness, not a contest or a pass/fail exam. Therefore, while your task is to ride until the absolute last moment you are able, the goal of the test is to capture an accurate understanding of your ability, to which your future workouts are calibrated in intensity. Whether your FTP is found to have increased or decreased, an accurate result is a successful result as it will help you get the most out of your training. At the end of the test, you are given the option to accept or reject the results, so if you prefer you can keep your current FTP or manually adjust it.
How is FTP calculated from the Ramp Test?
We use 75% of your best one-minute power output as your FTP. It’s important to follow the target power as closely as possible as you progress through your test, but if you are above target for the final minute, the app will automatically reduce your result by a small amount. You do not need to finish a full step in the ramp for the test to be accurate, simply ride at the target power until you are unable to continue, whenever that occurs.
How to Perform the Ramp Test
The Ramp Test is simply a graded exercise test. Your goal is simple: ride as close as possible to the target power for as long as you can, until the point at which you can no longer sustain the effort. It begins with a really easy 5-minute warmup and then every minute thereafter it gets slightly harder, and typically takes about 25 minutes to complete (including warmup and cooldown). Because the test is so short and includes a warmup it requires no special preparation aside for being reasonably well-rested and making sure your power meter or trainer is recently calibrated. Stay in the saddle the entire time, but use whatever cadence feels most comfortable. For specific details of the test click here.
When to Take the Ramp Test
The ramp test should ideally be taken every 4 to 6 weeks to ensure your workouts reflect your most recent fitness. It should also be taken after any long break from training, such as after illness or injury. Conveniently, all TrainerRoad training plans begin with a scheduled Ramp Test to assess your fitness and calibrate your upcoming workouts, and most Build Phase plans even include a ramp test midway through, to plot your progress. Since the test is short and relatively low-stress, you can test often without worrying about accumulating extra fatigue. You do not need any taper or special preparation in the days leading up to the test.

Indoor Training
Make the most of your hard work with an optimized indoor training experience.
Check Out TrainerRoadGroup Ramp Tests
Ramp tests can also be completed using TrainerRoad’s Group Workouts feature – you can share video and audio with up to ten other friends while simultaneously taking the ramp test. Group ramp tests are great for providing an extra bit of motivation, to help push each other just a little bit harder. Each rider’s target power is individual to them and their results will be based only on their own ride, but real-time data from each rider is visible to everyone else in the group. For more about Group Ramp Tests click here.
Advantages of the Ramp Test Over Other Formats
Traditional FTP tests are challenging and very exhausting. Not only do many riders avoid testing outright, riders who do perform traditional FTP tests often fail to complete them properly, or perform them poorly and need to redo the test. Worst of all, traditional FTP tests often yield questionable results that miscalibrate an athlete’s training. To make the Ramp Test the best and most efficient fitness assessment for cyclists, the TrainerRoad ramp test addresses a number of factors that often impact the success of more traditional testing methods:
Data-Driven
Over 7,000 tests were completed during our beta period with the new Ramp Test, and hundreds of thousands have been completed since it was officially released. The test’s format and calculations are optimized to improve your training benefits from subsequent workouts. Our data shows that riders who take the ramp test fail workouts at a lower rate than riders who don’t test or who use other testing methods such as the 8- or 20-minute test. In fact, riders who don’t test at all when starting a TrainerRoad plan are 3x likelier to fail their first workout than riders who take a ramp test. In addition, athletes who haven’t taken a ramp test in the last 90 days are 31% more likely to cut their workouts short. By taking the ramp test whenever it is scheduled in your training plan, your workouts stay more closely matched to your fitness and you’ll get better results from TrainerRoad.
Pacing is a Nonissue
Even pacing over long durations is crucial with traditional testing protocols, otherwise your FTP estimate and training will suffer as a result. Pacing is a really hard thing to nail, and even experienced riders can struggle. The Ramp Test eliminates pacing from the equation altogether. Resistance increases every minute at a steady rate and you ride until you can’t maintain target power any longer.
You’ll Never Have to Retest Due to Failure
When riders simply guess at their FTP without some assessment protocol, they have a tendency to overinflate it. This comes at a great detriment to all the workouts that follow.
The Ramp Test begins at a low percentage of a rider’s previous FTP, and increases intensity until the rider reaches a point of failure. This structure has proven not to overestimate FTP. Even if a rider under or over estimates their FTP coming into the Ramp Test, the test starts at such a low intensity and ramps up so gradually that we’ll always get a usable and accurate result.
You Don’t Have to Switch Trainer Modes
With traditional testing, riders have found it a bit confusing with mode changes on electronic trainers. The Ramp Test solves this. Riders simply choose one mode and stick with it for the entire duration of the test, and we recommend leaving your trainer in whatever mode you normally ride in. Smart trainers with ERG mode offer no advantage or disadvantage over traditional trainers.
Less Overall Stress on the Body
Unlike traditional tests that require maximal effort for extended periods of time, the Ramp Test really only hurts for the last 2 or 3 minutes and then you’re done. This means less stress on the body overall, less recovery is required, and you have the option to follow your test up with a structured workout.
In summary, the Ramp test is the new preferred testing protocol to estimate fitness because it:
- Does not require even pacing
- Does not require trainer mode switching
- Is easier to repeat precisely
- Is less stressful on the body, allowing for a follow-up workout
- Hurts less
- Takes less time
- Allows for the most effective training
Tips to Nail Your Ramp Test
While the Ramp Test is short, it can be challenging, so it’s essential to prepare before completing it. You’ll want to make sure you’re reasonably rested and fresh. Additionally, you’ll want to make sure you’ve got some nutrition on board, so eat a carb-rich meal 3-4 hours beforehand. Finally, make sure you got at least one good fan pointed at the trunk of your body. For more tips on FTP tests, check out How to Get Your Best FTP Test Results.
Ramp Test FAQ
Do you still have the old 8 minute and 20 minute FTP tests?
Yes, the 8 minute and 20-minute test aren’t going anywhere and you can still use them if you prefer them.
I went into the test fatigued and got a low score. I thought the Ramp Test is less dependent on fatigue?
While the new test may take less time and may exact a smaller physiological toll on the athlete, it is not any easier. You do need to be reasonably recovered and prepared for any assessment workout in order to obtain usable results.
Can/should I do the Ramp Test more often than the traditional 8 or 20 minute tests?
We still recommend assessing every 4-6 weeks. If you’ve taken some time off from training, resume training following an FTP assessment workout.
I’m a steady state athlete (TT or triathlon). Should I do the Ramp Test or is the 20-minute test a better assessment for me?
We recommend the Ramp test. Even though the intensity of the effort required during the final steps of a Ramp Test is well above the intensity required during a longer, lower-intensity effort, the information gleaned from the ramp protocol is more accurate than an FTP estimate based on a poorly paced 8- or 20-minute test. With a sufficient level of commitment and freshness, this format leaves little room for error in cyclists of all disciplines.
What if I score higher on the 8 minute or 20 minute FTP test?
If you score slightly higher we recommend you still take the Ramp Test result and see how training goes. We’ve seen a lot of athletes not fall into the 90% and 95% reductions on those tests and they struggle doing sustained threshold work or any Vo2 max work after “overtesting”. As you train, if you feel that typically very hard workouts are just too easy you can always manually adjust your FTP.
If you score a big difference in FTP between testing protocols we recommend you check the following:
- Did you REALLY dig deep and go hard?
- Are the two tests recent and on the same equipment?
- Do you have excessive fatigue?
- Did you have a major power dropout during your Ramp Test?
- Were you able to achieve a level of performance similar to recent PRs?
Can I increase the warmup?
Due to the very low-intensity nature of the warmup and the fact that it’s scaled to your previous or predicted FTP, this assessment incorporates a sufficient warm-up period that will adequately prepare riders for the higher-intensity steps that will close the ramp assessment. If, however, you’d prefer to add a few extra minutes of warmup time prior to beginning the Ramp Test, do so every time you perform a Ramp Test in order to keep the results and protocol consistent.
Should I do the test in aero position?
Yes. If you plan to race and do the majority of your training in the aero position, testing in the aero position is recommended. Aero positioning often recruits the pedaling muscles in slightly different manners than more upright positions. Aero positioning also changes the stress on other, less obvious muscles which can contribute to the strain you’ll experience when training or racing in an aero position. So establishing an FTP that is specific to these altered demands is appropriate.
Should I do this test in ERG mode?
If you have a smart trainer we recommend that you do the test in ERG mode (default). A smart trainer is not required and those doing the test in ERG mode do not have an advantage over individuals on a traditional trainer.
What is a good ride to do after the Ramp test to keep my TSS inline with the 8/20 minute tests?
It’s not required to do a workout after the Ramp Test. But for riders who want to get a little work in, we recommend actively recovering for 10-15 minutes followed by one of these workouts:
For more cycling training knowledge, listen to Ask a Cycling Coach — the only podcast dedicated to making you a faster cyclist. New episodes are released weekly.
Or Skip the Test Entirely
The ramp test made FTP testing easier—TrainerRoad’s AI FTP Detection lets you skip it altogether, calculating your FTP automatically from the rides you already do. TrainerRoad AI then builds every workout around it and adjusts as you get fitter. It’s how cyclists have completed more than 30 million workouts and gotten faster.
Start Getting Faster with TrainerRoad — 30-day money-back guarantee.