I guess I’m focusing on other things. Or don’t really care. I don’t know. Just didn’t seem like a big deal.
I mean you do you, my criticism of it would still be what I posted above. If the llm you use gets the simple things wrong I would be very sceptical that it is going to be accurate on more complex matters.
A llm will be extremely confident in what they give you but will make things up all the time, so while the plan might look good at first glance it can easily be a poor one overall. Unless you have the knowledge to know where it goes wrong you won’t be able to tweak it into a good plan, but if you have that knowledge already then you are probably better off making your own plan in the first place.
1 Like
Just giving my reasoning for my prompt and answering questions as they came up. If it came off as defensive I’m not sure what to tell ya. I don’t have any stake in AI. Just felt like changing up my training a bit and thought it would be fun. Did seem to get some people riled up here though it appears.
Lol. You are free to stop reading the thread at any time or mute it if it bothers you this much. Part of the experiment was to post the results and how it was going throughout the plan. I’m not forcing anybody to keep reading. TR is a forum for training related stuff. This is a training related topic. It’s just meant to be a fun experiment and post my experience with it. If that offends you I guess you can always report me but I don’t feel I’m breaking any rules. ![]()
![]()
1 Like
Just my two cents before I stop posting: This experiment is not going to be very insightful if you rationalize away every flaw that is pointed out along the way. If this is truly an experiment then you should keep an open mind for the answer to the question in the title to be “no,” but that’s not how you’re coming across—it sounds like you’ve already made up your mind. Anyway, good luck.
2 Likes
Yea I get where you’re coming from and being skeptical is warranted. If somebody is giving advice and it sounds pretty reasonable, and then they tell you the earth is flat or we’re just living in a simulation, you start to question everything they said, even the reasonable stuff. So I get it. Could totally blow up in my face. That’s pretty much the point of the experiment. Who knows? Science is fun because you have a question, and then you test out that question and see what happens. Maybe I follow the plan and my FTP jumps 50W. Maybe I win every race I do. Maybe I burn out in 2 weeks and need an entire week off the bike. Maybe I try it for 6 weeks and I’m exactly where I started. It’s fun to try new things. I’m not paid to ride my bike so I can do whatever I want. I’m still riding my bike and that’s the most important part.
2 Likes
I get where you’re coming from. But I also disagree with the basis of your comment. And actually think I am the one keeping an open mind and sticking to the idea of testing an experiment. What I mean by that is, if you take the question, “Can ChatGPT give me a good training plan to get faster?” Then I shouldn’t be changing it based on any of the advice here. Not to say it’s not good advice. Likely the opposite. I know a lot of the advice is really spot on. But that’s not the point of the experiment. If the question was can the TR forum design a good training plan then yea, I’d be taking the consensus from here and making a plan. But the whole point was to use ChatGPT exclusively. So while it may appear that I’m just dismissing the advice here or rationalizing it all away, my answer is that’s the point. The experiment was to use the plan from ChatGPT and see what happens. So yes, the whole point is to not listen to advice here. So I’m not dismissing it for the sake of dismissing it. My goal was just different. It was to see if ChatGPT could design a plan. I have made up my mind to try the plan. That’s the whole point. What you’re suggesting would be like designing a research project and then changing everything halfway through and thinking you can still reliably answer the original question. It’s bad science.
It’s funny because I feel like I’m the only one who IS keeping an open mind in regards to the point of the experiment. I get that some people see and point out flaws. That’s the point. I see that some people think it’s too much intensity. Again, that’s the point. The point is to test the plan it gave out.
It’s like this. I have a new medication to lower blood pressure. I want to give 10mg to lower somebody’s blood pressure. Some people think that dose is way too high and will kill people. Other people say I should give it twice a day and it will work better. But the question is will once a day at 10mg be effective? If then change it and start giving 5mg three times a day, can I reliably answer the original question?
That’s kind of how this thread is going. I am totally aware that the plan might fail spectacularly. I am aware of the critiques. And agree with some. But the point of the experiment was to just follow ChatGPT and see what happens. So while I could change the plan as suggested, it kind of defeats the whole purpose. You know?
3 Likes
Awesome
Long post incoming. @JSTootell @giventotri @Twowkg @OreoCookie @Power13 so you can read it or not.
So I went back and reread everything. I looked over my initial post and all the replies, and my replies as well, and thought about it for a little bit. And I think there’s just been a misunderstanding of the intent of my project. So I get the frustration that some people have had with my responses. And I apologize. And I guess I can take some blame for maybe not explaining it how I had it in my head. So I thought about it and came up with a hopefully simple analogy.
It’s like I said, “I’m going to X restaurant and going to try the lamb and review it.” And what the responses have felt like to me is someone coming in and saying, “well I’ve been reviewing steaks for 20 years. I think you should get the steak it’s a better choice from this restaurant.” And then somebody else comes in and says, “no I think you should try the vegetarian options. They’re healthier and they’re pretty good. I think you should try those.” And then somebody else comes in and goes, “if you want lamb you should go to this restaurant instead.” Meanwhile, I’m just sitting here like I just wanted to try the lamb. I’m not saying the steak or vegetarian options are bad, just that my choice was to try the lamb.
So what I mean by that is I think that I didn’t fully explain my intent. But before that, I have to say that I love TrainerRoad and I love the TrainerRoad forum. This forum is an absolute invaluable tool for anybody in cycling. There are so many smart people on here. And I can say from experience, I’ve gotten such great advice. I have no doubt that a lot of people on here know more about training than I do. But it wasn’t really the point of this thread. It was really just to have fun and try something different. I’ve tried TrainerRoad over the years. I’ve tried a real person coach. I came back to TrainerRoad. I think mainly I’m just bored. And I wanted to try something new and different. I’m not paid to race. I don’t have a team that relies on me. I race and ride for fun. Which gives me a lot of freedom to do whatever I want. So this wasn’t like a situation where I’m thinking “I wanna do sub-8 at Leadville and I need a coach or training plan that’s gonna get me to that goal.”
It was really just like a shower thought saying, “Hey I wonder if ChatGPT can give a training plan that would work?” Or more simply, “what would happen if somebody followed a ChatGPT coach exclusively?” And so I think a lot of the responses that I was giving was not because I think they’re wrong. It was just that I was more just curious to see what would happen if ChatGPT dictated all of my training. So I apologize if I didn’t fully understand my plan or what I was trying to accomplish. I also apologize if some of my responses came off as being defensive or dismissive. I wasn’t dismissing your training philosophies or general ideas about training. I was just trying to say that they weren’t what I was looking for in this very specific instance.
I said it above, but I’ll say it again. This isn’t designed with the sole goal of trying to get X watts faster or getting a certain time on a course. It’s just for fun. I could end up at the end losing 50W on my FTP. [insert James May meme “Oh no. Anway”] To me that’s part of the fun. Try something new and see what happens. That’s all this was meant to be.
So if that doesn’t interest you I’m fine with that, I know it probably doesn’t interest a lot of people. I’ll probably limit updates to once a week regarding training. But if anybody has questions specifically or comments, I’ll try to read them and respond. Hope that clears things up. Cheers.
4 Likes
Both. Still in the between seasons phase here so it’ll be 30F one day and 70F the next. Today was on the trainer.
Fine so far. Endurance yesterday, 1:45, 60 TSS. Today was a Sweet Spot workout, 3x15 with some Z2 at the end. The intervals ended up being 92/94/93%, 2:00, 118 TSS. The given workout was 3x15 @92-95. I chose the TR workout Tallac, which is 88-94% and just increased the intensity to 103% to get a closer workout. Felt good, rated it Moderate. I have a Threshold workout tomorrow, 4x10 @100-105%. We’ll see pretty quick how my legs respond.
CTL 78, ATL 88, ramp 2.7 according to TP. Probably should have added my starting point (CTL 77, ATL 86, ramp 3.1).
Edit: It’s already made a change. I uploaded the day’s ride metrics and stats, along with RPE. It has changed my upcoming SweetSpot from 4x15 to 3x18. So it appears to already be learning that 3x15 to 4x15 is too much and suggested progressing to 3x18 instead.
2 Likes
I think a better analogy would be starting a thread titled “Can AI make good pizza?” with an LLM-generated recipe, getting a few replies pointing out the recipe has glue in the sauce for some reason, and then insisting on trying it anyway in the same of science. To your point, I think the mistake a few of us made was not realizing the question in the title was purely rhetorical and you weren’t looking for feedback, but I think we were simply trying to say “if the sauce has glue, maybe you should be skeptical about the rest of the recipe.”
I don’t have a horse in this race so I probably won’t be checking back on the results, but good luck, I hope it works for you and you get what you’re looking to get out of this.
3 Likes
That’s actually sounding like a fun idea and will definitely be trying this in the future. And if you said something realistic instead of glue, like the recipe said flour, ground pepper, and yeast for the dough, I think it would be a spot on analogy. People would be like, you don’t make dough with pepper you need salt. But I try it anyway for science. And to be honest, I don’t see anything wrong with that. Again, that’s literally the point. You ask a question, and test that question. That’s science. And exactly what I want to try. Maybe the pizza tastes like absolute garbage. Who cares. Maybe it suggests some weird ingredient that I never would have thought of and it tastes good. The point is trying something new.
And I totally get that. I just don’t think it was suggesting glue.
I believe @giventotri was referring to a well known case of an LLM actually recommending glue as a pizza ingredient.. The point being that the poor choices in this plan should be as obvious as that.
2 Likes
Did not know that. Haha. TIL
That is in itself a fundamental misunderstanding of how AI works.
LLMs generate outputs based on statistical patterns, not logic or understanding in the human sense. This means they might stumble on something trivial but still deliver strong, structured reasoning on technical or nuanced problems. You wouldn’t reject a human expert for forgetting a date, nor would you throw out a GPS because it gave one wrong turn. Judging an LLM based on isolated failures, especially in unrelated domains, is poor methodology.
The better approach is to evaluate how well the LLM performs on the specific tasks you care about. If you’re using it for deep analysis or synthesis, test it in that context—not based on whether it messes up a trivia fact or makes a typo.
And of course you always have the option to continue to prompt the AI and give it frank instructions which it can interpret in order to get you more in the direction. If you suspect it made an error with the “simple things” you could prompt for that.
The problem with a general purpose LLM is that it’s read every bad training plan ever posted the internet and regurgitated it with no intelligence. Now if someone trained one with solid tried and true information, it might spit out something ok.
4 Likes
I think you are mistaken: the value isn’t in the algorithm FasCat uses, but it is in the training dataset. That is unique to them and I am not aware of anyone else possessing such a dataset.
At my previous employer, I was part of a team that applied ML algorithms to further develop its products (I’m intentionally vague here). A single “data point” cost well in excess of € 10k, and collecting and preparing the datasets was about 90+ % of the work in terms of time. We were unable to do things that are technologically easy, because e. g. the classification work required would be too time consuming for the few experts in this one field.
Except that this will not get you very far. To do any reasonable analysis, you need to have subject matter expertise and experience in statistics (as well as ML if you choose to apply those methods). For a serious effort, you’d likely need to collaborate with subject matter experts from both sides. Needless to say, this is rare. Further, it is N = 1, which severely limits what you can glean from the data.
1 Like
This.
And this means there are two important aspects, which models like Chat GPT currently do not have: the datasets they have been trained on have not been vetted for accuracy and consistency. And the datasets they have been trained on is very broad.
In that setting you need enough subject matter expertise to have a well-developed BS detector. (That’s something my students are missing when they try to let ChatGPT do their homework, I’m speaking from experience.) For if you don’t, you cannot rely on the response — unless you are ok with glue in your pizza or being overtrained/badly trained. Kinda like how some people followed their GPS’ instructions right into a river.
I would even take another step back and ask myself: would a general-purpose LLM be the right tool for the job?
That’s why I have suggested several times to @Eddy_Twerckx to also try out CoachCat, which is a LLM specifically made to help cyclists train. It has been trained on a good, focussed dataset (with good I mean as judged by Frank Overton and his staff, absorbing their training philosophy). I’d be very curious about that.
Asking ChatGPT about structured training for cycling is like asking me about soccer and expecting a well-informed response. ![]()
3 Likes
Oh, absolutely. I expect that this is a major part of their work and I expect that the institutional knowledge TR has amassed since it started its journey on ML several years ago will be extremely hard to replicate.
Just think about e. g. how finicky heart rate data can be. Sometimes it takes a while for my Rival to connect to my Bolt. Sometimes the Rival locks onto my cadence. My Tickr sometimes got “stuck” at 200+ bpm, etc. etc. Add to that factors like power data from different sources for the same athlete. Tons of issues I can come up with without knowing how to best solve or at least mitigate them.
I am certain this was also a factor as to the hesitation of TR to allow Zwift to do its workouts: because now Zwift can build its own dataset where it can compare what athletes should have done with what they have actually done and the training outcomes. TR’s dataset is its moat with which it can keep the competition at bay. FasCat wanted to use the same tools, but doesn’t have the same kind of datasets. So instead, they used what they had, which I think was very smart. I would really like to know how well it works (although I am not willing to experiment on myself).
Yup.
That’s where subject matter expertise comes in, combined with a solid background in statistics. You can easily ask “stupid” questions or try to optimize for the wrong metric. Finding the right questions is hard.
2 Likes
I might actually try that next. It would be a cool comparison. Use a dedicated cycling training AI vs a general LLM. I would expect the Fascat AI to be much more in tune with training and probably get me better results. And require much less guiding and redirecting.
Yea, I agree that TR’s data is probably their biggest weapon. They have so much training history to go off. And like you said with Fascat, the training dataset you’re building the AI from is hugely important.
1 Like
It’s still early (only 2 workouts in) but it’s made two changes. The first being changing the progression on the SweetSpot workout it scheduled for Sunday. It originally had 4x15 @92-94%. After feeding it the workout info, it actually first changed it to 3x15 @94-96% (so increased intensity at the same duration). So I asked if that was still SweetSpot at that intensity and what was the idea behind increasing the intensity rather than increase duration.
“There are two primary ways to overload Sweet‑Spot work:”
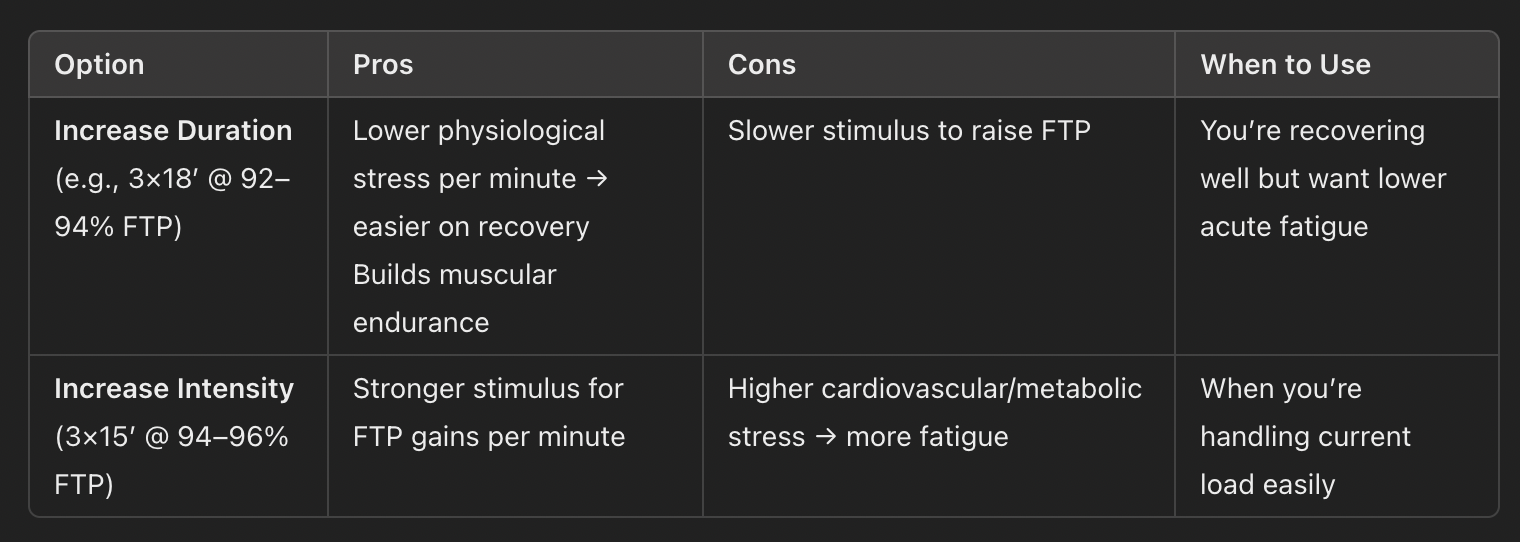
So I asked if we should increase duration or intensity.
“Given your feedback (“felt tough but manageable” + minimal soreness + solid sleep) I’d lean toward increasing duration first for a gentler progressive overload.”
So then it gave me the 3x18 @92-94%.
I’m thinking it sensed the hesitation in my questioning about increased intensity and tried to please me by switching to increased duration instead.
Now even with that I’m still thinking it’s too much for a single week (2 sweetspot, 1 threshold, 1 VO2). So we’ll see how it changes further.
The second change was minor. I asked if the plan was still for threshold today. And it said “Yes — stick with tomorrow’s Threshold session, but we’ll tweak it slightly to account for yesterday’s solid Sweet‑Spot performance and your ongoing fatigue status.”
It just tightened the power band from 100-105% to 100-102% and said to aim for the lower end.
"Execution Tip
- Start conservative: Hit the low end of target for the first interval, then slightly increase if you feel strong.
If you feel unusually fatigued tomorrow morning, we can reduce to 3×10’ at the same intensity. Otherwise let’s push for the full 4×10. Let me know how you feel pre‑ride!"
1 Like