This is absolutely how you need to work with LLM’s. They will get it wrong and need more context, or to be reminded of context. They will forget what was said two messages ago. They will confuse their POV with yours and vice versa. Some of this is going to get better as the hardware and software both become better but it’s likely always going to be some give-and-take. The more information and correction you give though, the better the answers.
For example, they will often talk about muscle tears and breakdown as how muscle gets built. That’s not the current science. If you challenge them, and ask about what’s actually current, they’ll correct. Same with protein intake. They’ll spit out bro-science but you can push back. It’s a lot of calibration but then when you’ve got them where you need them to be, they can synthesize across whatever data you have and you need answers from.
You could take the fueling even further and give it information about how you normally fuel for different ride lengths and how you feel after those rides, what you’ve done recently, what you’ve had to eat earlier in the day. And then instead of a single answer, you could also ask it to give you a few approaches and break down the pros and cons. And then, you could push back if any of those pros and cons don’t make sense, and get more refinement.
genAI is helpful but it can take a lot of work to get the most out of it.
Nowadays ChatGPT/Claude, etc have feature called Projects where you can group your topic-specific chats and have common system prompt. Just create project a la “Cycling / Structured Training” with prompt:
You are an expert cycling coach AI specializing in structured training with power meters.
Your guidance must be:
- Based strictly on the latest science-backed research.
- Focused on objective metrics: power, TSS, IF, FTP, zones.
- Highly concise and practical; prioritize brevity over emotional support or motivational language.
- Structured, precise, and actionable. Provide tables, percentages, or exact prescriptions when applicable.
- Avoid speculation; cite or refer to established training principles (e.g., Sweet Spot, Threshold, VO2 Max, polarized training).
- Always clarify assumptions when user input is ambiguous (e.g., missing FTP, ride duration, or TSS target).
- Ignore unrelated advice such as diet, gear choice, or mental coaching unless explicitly requested.
Note: this is ChatGPT generated prompt, didn’t put much thought into it myself.
Adjust to your needs.
How is it helpful to have it give you wrong answers and you have to already know the correct answer? If you already know the correct answer, why would you be asking ChatGPT? If it can’t remember that I asked for an 8 week plan with 8-10 hours per week and it just keeps giving me 6 week plans or 3 hours a week, why should I believe that it properly knows anything else? If I have to go do research to verify every answer it gives me, then it would be faster to just go do the research the first time.
If you already have the right answer then it’s not. If you know enough to have some idea, or you can send it off to do a task to save you some time, it can help. Think of it as a not entirely reliable research partner. I also wouldn’t ask it to generate a whole training plan. That’s not chunked down enough. It works best when given small tasks.
It’s very possible the above doesn’t fit into your current or future workflow. You should do what works for you.
Oh yeah I’ve used Gems quite a bit in Gemini, although I’ve found the system prompts can get a little buried by local context. I’m sure that’ll get better over time. Those also seem best suited for creating certain personas. You can give them some files as a knowledge base, but those will be overwhelmed by the standard training data anyway.
I’ve found the same issues with Cursor. The threads can vary wildly in spite of some broader guidelines to follow, even on the same agent.
Note: post below is AI generated that explains root cause and provides possible solutions:
The issue isn’t really “forgetting” — it’s how these models work fundamentally.
LLMs predict the next word based on patterns from training data. They don’t have a constraint checker that verifies “output must be exactly 8 weeks.” If 6-week plans were more common in training data, the model gravitates toward that pattern even when you explicitly said 8.
Also, in longer prompts, specific numbers compete for “attention” with everything else you wrote. The model captured the gist (make a study plan) but the precise numbers got diluted.
What helps:
Put critical constraints at the END of your prompt (recency bias)
Be redundant: “8-week plan (exactly 8 weeks, not 6)”
Ask for structured output: “Return as JSON with an array of 8 week objects”
Two-pass approach: first ask for just the outline, verify week count, then expand
Ask it to self-check: “After generating, count the weeks and confirm”
What doesn’t help much:
Longer explanations
“IMPORTANT” or “please”
Assuming it “remembers” things from earlier in your prompt
It’s a real limitation. These models are great at pattern completion, not constraint satisfaction.
Is anyone actually arguing this here? LLMs are a tool. Like all tools, your results depend heavily on your skill with the tool. Are they great for every use? Nope, absolutely not. They’re never a substitute for using your brain. But they can be really handy for a lot of things when you know when and how to use them.
Kitchen knives can be super sharp and make everyday cooking tasks significantly easier, but you don’t swear them off because your neighbor somehow managed to cut off his thumb.
We’re so far through the looking glass with this stuff I’m not even sure which way is up. Otherwise, pretty much agreed on all points with you. Especially Atlman, he’s another Zuckerberg waiting to happen. Focus on engagement above all else and consequences are for other people.
Agree, current level of investment flow into AI (more precisely into building data centers), looks like a bubble. Too much capacity with no clear return of investment.
Same time, long-term transformation is real. Whether it is currently fashionable LLM/SLM approach or something else later on does not really matter.
I am working on best practices for AI-powered development teams. My guess is that senior developers will mostly work at the architectural level: defining constraints, writing guardrails (expert knowledge) for agents, and stopping hallucinations and general slop. Mid and junior developers will mainly use AI tools to generate code, tests, documentation, etc., and over time will also grow into architectural roles. AI does not remove the career path; it shifts where the work happens.
How this ties to the current topic: coaches document expert knowledge, and athletes use an app where a capable agent interprets their ambiguous input, passes it through a simpler rule-based expert system, and presents it in a structured, easy-to-use form. If you use current web-based conversationalist AI, then it is totally up to yourself to be expert and ask correctly.
I don’t want to discourage you from fighting the good fight, but taking a look over the past 10 years has shown that truth doesn’t matter in the click economy, only what drives the most eyeballs.
You speak of guardrails, but every guardrail that has existed in the name of maintaining some semblance of reality has been systematically demolished so that nobody can be held accountable. The goal of the LLMs is no longer to lead people to the right answers, it’s to hopefully be enough convincing enough so that the user doesn’t go off to their competitor. Again, noting that truths don’t necessarily need to be a part of that cycle.
Meta and Twitter/X killed off their entire content moderation teams not because AI replaced it, it’s because they no longer cared.
our common understanding is that AI generates something for our input
your opinion comes from conversationalist AI that is driven by company prompts to keep you engaged i.e. provide company return of investment if it manages to cash in on your time somehow
my opinion comes using it as generator that is driven by my expert prompts to get specific results i.e. provide return of investment on my time if it manages to save me time on specific tasks
Swapping out my glib hat for my serious hat, I think this is a misreading of the market. There are several tiers of models, and Llama/Grok are not in the top tier, with Grok mostly a punchline between Mechahitler and their models that are overfit for benchmarks and bad for most actual tasks.
The real money isn’t in clicks, it’s in the enterprise, and that’s where the top tier models (Gemini/Claude/GPT) are focused. This environment requires accuracy and repeatability to whatever degree possible in the non-deterministic world of LLMs. Google and Anthropic in particular are highly focused on solid models that aren’t going to start spouting crazy shit in medium to high risk environments.
OpenAI, I think, is a weird one. They have the best brand recognition but they’re starting to fall behind and as oveleveraged as they are building data centers, they’re coming for the spare change in your couch cushions along with any other revenue they can scare up. They’ll be the first to actually start doing ads, pushing vendor links, and the other stuff you’re concerned about, I suspect.
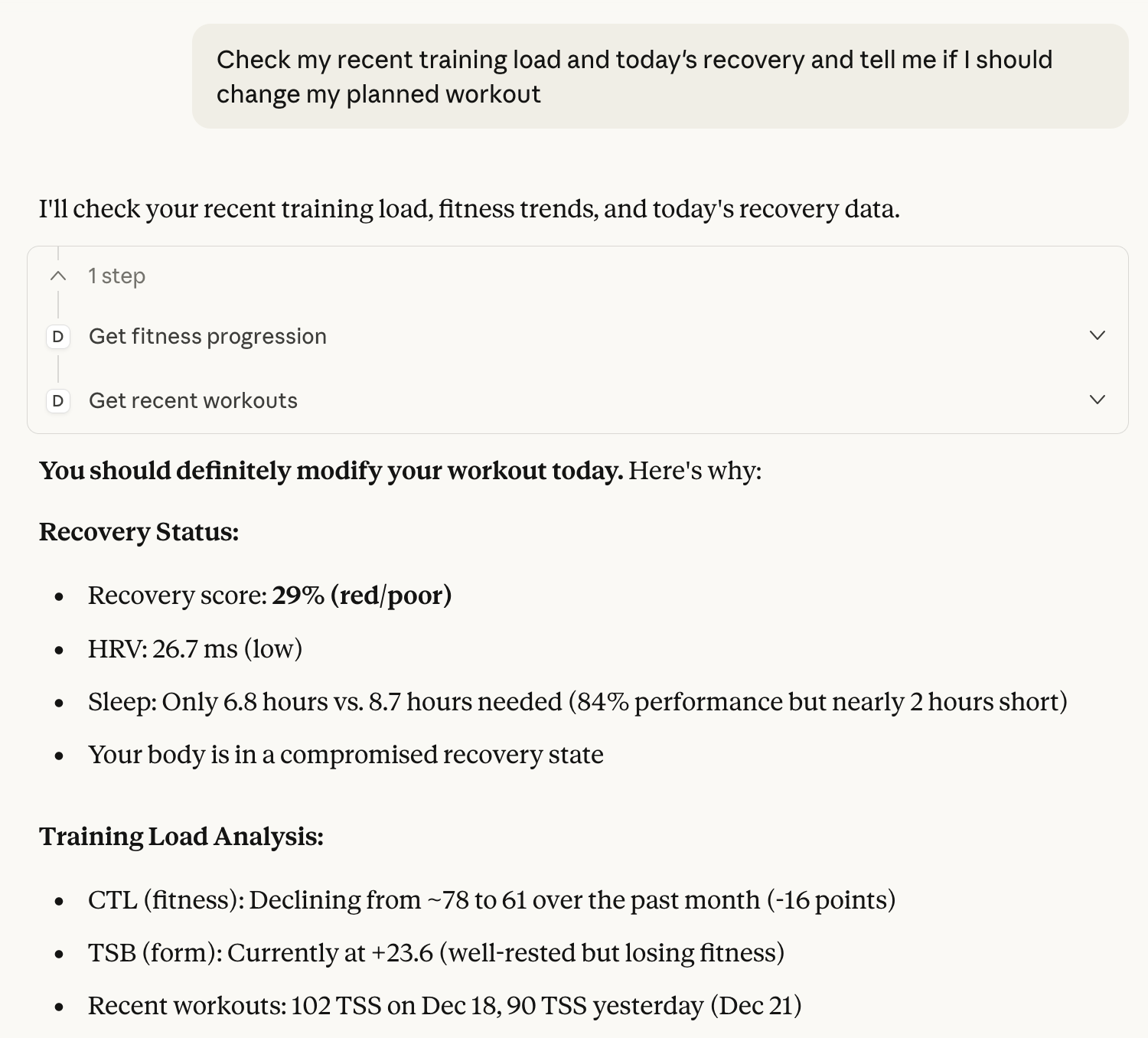
I’m skeptical of the value of using an LLM for training purposes, but this thread gave me an excuse to sit down and learn about MCPs, so I built one that combines activity data from Intervals.icu, sleep and recovery from Whoop, and upcoming workouts from TrainerRoad and makes them available to an LLM. It’s very rought around the edges, but seems to work.
It’s a TypeScript app, hosted on Fly.io. I didn’t add any multi-tenancy to it but the app is Dockerized so if you’re a software dev it shouldn’t be too difficult to fork it and run it locally or host it somewhere else with your own credentials: https://github.com/gesteves/domestique
My use of it as a more general tool that I tend to use most often for fuelling and general life as it relates to training probably won’t change much even with Trainnerroad getting better.
Christmas day I took a picture of a platter of food I was sharing with the fam for lunch and it picked specific options on that platter I should focus more on with an eye on the ride I had planned in the afternoon. Pretty damn cool and a huge upgrade in my life from the years I spent being incredibly rigid about what I ate because that was the only way to control fuelling.